Docker启动Kafka
1 | 172.17.0.2:2181是通过docker inspect zookeeper --format="{{ .NetworkSettings.IPAddress }}" |
简介
消息队列:一个系统向消息系统发送数据,另一个系统从消息系统获取数据
消息:Message、Record、Data、Event
标准消息系统中分为三大组成部分:生产者、消息队列系统、消费者

为什么需要消息队列?
- 异步:不同子系统之间无关,消息传递应该是异步的,提升系统的总体性能
- 解耦:耦合性太强,扩展性太差,希望解耦合
- 消峰填谷:缓冲上下游瞬时突发流量,让其更加平滑
消息传递数据的方式?
- JMS:Java Message Service,和平台无关的消息服务接口
- 要求:
- 消息发送必须是异步的;
- 保证消息只会传递一次;
- 定义了消息模型(点对点;发布-订阅)
- 要求:
消息队列产品的特性
- 必须是开源,比较流行
- 确保不丢消息
- 支持集群,保证服务可用
- 性能足够好,能满足绝大多数场景
主流消息系统
RabbitMQ:
- 对积压消息处理的不够好
- 如果有大量消息积压,性能会严重下降
RocketMQ:
- 国产消息队列,在国际上不流行,与一些国际包集成与兼容做的不够好
Kafka:
- 兼容性最好,其它开源软件都会优先支持Kafka
- Kafka使用Scala和Java语言开发,大量使用批量和异步思想进行消息处理,具有优秀的性能
Pulsar:
- 新兴开源消息队列产品,兼容Kafka
为什么选择Kafka?
- 处理消息快:每秒处理几十万、几百万消息
- 高并发:同等配置机器下,可以拥有更多生产者和消费者
- 磁盘锁:锁住磁盘IO的场景非常少,等待时间短
Kafka中的组件
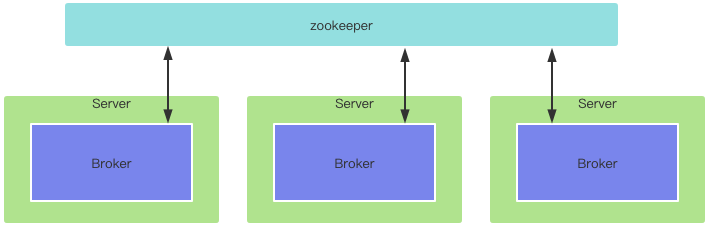
Broker
Kafka中提供消息读写服务的节点称为Broker,应该是分布式部署,而且互相之间独立,每个Broker节点在集群中具有唯一性标识(配置文件中的broker.id),不能重复。
分布式集群经典架构是主从,多个Broker如何管理?
- Kafka使用的zookeeper进行管理
- 所以Kafka严重依赖于zookeeper
Topic
Topic是承载消息的逻辑容器,在实际的使用中用于区分不同的具体业务数据
Topic是Kafka中消息队列的标识,也可以认为是消息队列的ID,用于区分不同的消息队列
意味着其中存储了很多消息

创建
1 | kafka-topics.sh --bootstrap-server 127.17.0.4:9092 --create --topic test_topic --partitions 3 --replication-factor 2 |
查看
zookeeper中:
1 | ls /brokers/topics/test_topic/partitions/ |

"Isr":[2,0]:表示它的同步副本在id为0和2的节点上
Partition
所有消息都放在一个Topic中,有可能会产生服务“过载”,所以将一个队列拆分成多个队列,让数据可以均匀分配,达到负载均衡。
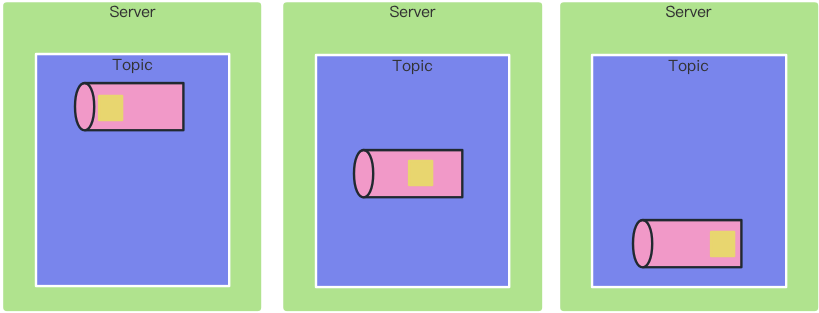
因为数据可以放置在不同节点的位置,所以可以适应任意大小的数据,这里的队列称为分区(Partition),所有分区的数据合在一起是完整的数据。
- 这样如果某个节点不可用,则会导致这个节点的数据不可用,为解决这个问题,保证数据可靠性,提供了副本机制(Replica)
分区的目的:
- 负载均衡
- 扩容数据
- 快速消费数据
Replica
副本机制:为了保证数据的可靠性,kafka为每个分区提供了多个副本
多个副本形成主从关系,其中一个称为leader(主)副本,其它副本称为follower(从)副本
不同副本放置在不同节点上,副本数量不应该超过服务节点的数量,因为没有意义
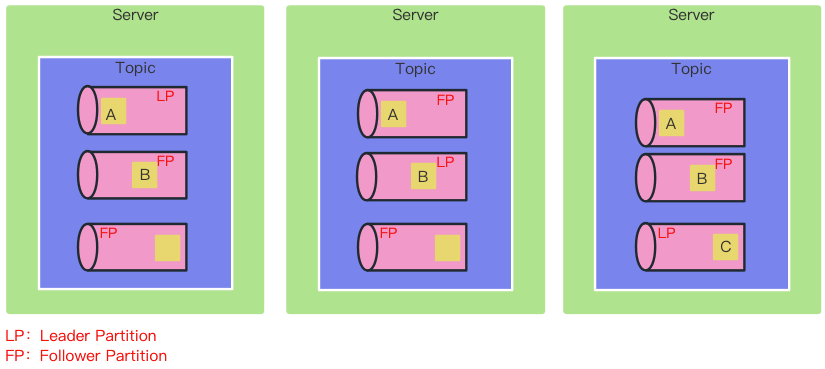
Leader副本主要用于读写请求,Follower副本主要用于备份,不参与读写。
Follower副本的数据都来源与Leader副本
Leader和Follower副本主要是争抢资源
分区和副本如何存放?
Kafka在分配分区和副本时,会从当前集群中随机找一个节点来存放第一个分区,然后再轮询存放
分配原则:
- 将副本平均分布在所有broker上
- 一个分区的多个副本应该分配在不同broker上
- 如果一个broker有机架的话,则副本应该分配到不再的机架上
Log
数据日志文件
每个分区可以视为一个无限长的数组队列,新的数据可以追回到这个数组中,数据在分区中的位置称为偏移量offset
一个分区的数据都放在一起,内存无法放置太多,所以需要写入磁盘,磁盘IO会极大影响写入速度,为了性能考虑,磁盘文件不能随机访问,只能顺序访问。
如果所有数据都写入一个文件,如果想要快速消费数据,需要将文件进行拆分,称为分段日志文件(segment),文件拆分配置通过log.segment.bytes进行修改
为了能够快速访问文件中的数据,Kafka还会生成索引文件
日志文件存储目录由log.dirs进行配置,日志文件查看通过kafka-run-class.sh kafka.tools.DumpLogSegments --files xxxxx.log
RPC通信
- SocketServer.startup():启动服务
- requestChannel.sendRequest(req):发送请求
- req = requestChannel.receiveRequest():接收请求
- KafkaApis.handle(req):处理请求
Controller
Kafka中如果所有节点的管理和消息的管理都由zookeeper管理,会导致大量的读写请求操作,而这并不是zookeeper擅长的。
Kafka解决策略:从所有Broker中选举一个节点作为管理者:controller
如何选举?
所有节点向zookeeper发送创建节点的请求,第一个创建成功的节点就是controller
zookeeper中的/controller节点是一个临时节点,一旦和broker失去联系,这个节点会消失
一旦节点消失,则所有节点都会被监听到,重新争抢节点操作,谁先抢到谁就是controller,同时选举编号会累加,累加后,集群中所有节点都会遵循最新编号的controller操作
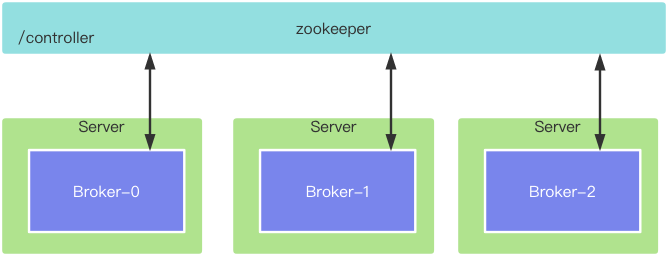
controller管理集群的全部元数据信息,将这些信息同步到其它broker中,而其它broker只和controller交互,不和zookeeper连接
服务器配置计算
假设有100万日活*100条(用户行为数据)=1亿条
1亿条数据*1KB=100G
凌晨12点~早上8点数据量很少,可以忽略不计,所以1亿条/(24-8)*3600s=1750条/s=1750KB/s=2m/s
峰值通常为平均的2030倍:峰值=40m/s60m/s
公式:服务器数量=2*(生产者峰值 * 副本数量/100) + 1
服务器数量=2 * (60m * 2/100) + 1=3.4 = 4台
磁盘大小:数据量 * 数据冗余数 * 保存时间 / 空间占比
磁盘大小=100G * 2 * 3 / 0.7 = 1T(100G数据,1份数据冗余,保存3天,Kafka占用70%空间)
内存大小:数据量 * 保存时间 / 内存占比
内存大小=100G*3/0.7 = 300G~500G,到每台服务器上约128G
Kafka为什么快?
- 批处理:一次发送多条消息
- 客户端优化:新版客户端摒弃单线程,采用双线程模型,主线程负责将消息置入客户端缓存(缓存会将多个消息聚合为1个批次),Sender线程将缓冲中聚合好的批次消息发送到Broker
- 设计优良的日志消息格式:新版本日志消息格式引用变长字段Varints和Zigzag编码,有效降低了附加字段占用的空间,降低了网络传输、日志存盘占用开销
- 消息压缩:Kafka支持多种消息压缩格式(gzip、snappy、lz4),能极大减少网络传输量、降低网络I/O,提高整体性能
- 分区:对消息进行分区,提高了数据生产与消费的并行度,有效提升数据吞吐量
- 索引:Kafka为每个日志分段文件提供了2个索引文件(偏移量索引文件.index和时间戳索引文件.timeindex),提高消息查询效率
- 顺序写盘:Kafka在设计是采用文件追加方式来写入消息,而操作系统针对线性读写有做深层次优化
- 页缓存:减少对磁盘I/O操作;维护页缓存和文件之间的一致性交由操作系统负责,比进程内维护更安全有效
- 零拷贝:使用Zero Copy提升消费的效率