消费模型
一个消费者不分区的基础模型
问题:消费速率太慢
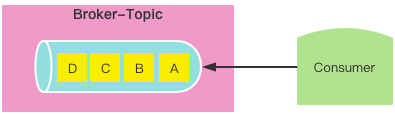
一个消费者不分区的基础模型 一个消费者消费多个分区
问题:数据乱序
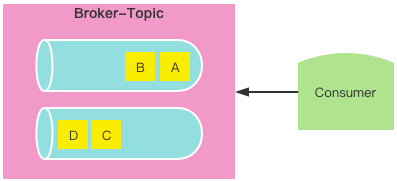
增加消费者消费数据
问题:如果没有合适的消费策略,会导致消费混乱、重复消费
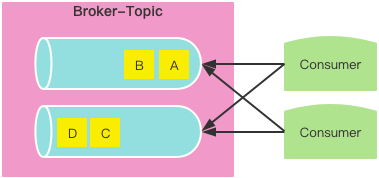
多个消费者消费数据 将多个消费者管理起来,形成整体(分组)
定制消费规则:消费策略
问题:
- 数据还是可能乱序
- 如果消费者组里面增加了一个消费者,且没有未消费分区则不消费
- 如果消费者组里面减少了一个消费者,则必须重新分配资源
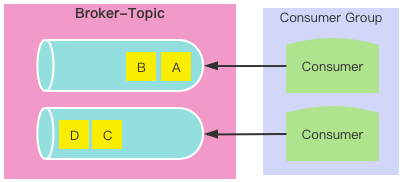
分组消费
Kafka消费模型
Kafka消费数据以消费者组的方式进行消费
一个Topic中的分区数据只能被一个消费者组中的一个消费者消费
一个消费者组的消费者数量不应该大于主题的分区数量,因为没有意义
如果组内消费者出现故障,则必须重新分配资源,将这个重新分配资源的操作称为重平衡,但是重平衡非常耗性能,所以能不做就不做
消费策略谁制定
消费者组中有一个管理者称为Coordinator,主要用于管理消费者组上线、下线等
Kafka会选择位移主题的Leader(Broker)作为Coordinator
Coordinator会将第一个加入的Consumer作为Leader,其它Consumer就是Follower
Leader来决策消费策略,将策略上传到Coordinator
其它Consumer加入后就会获取消费策略
消费策略怎么定
Kafka默认提供了4种消费策略,默认是范围策略
范围策略
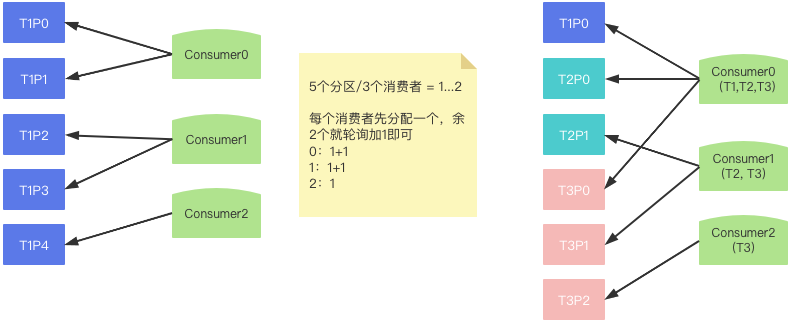
范围策略 问题:每个消费者消费能力不一样
轮询策略
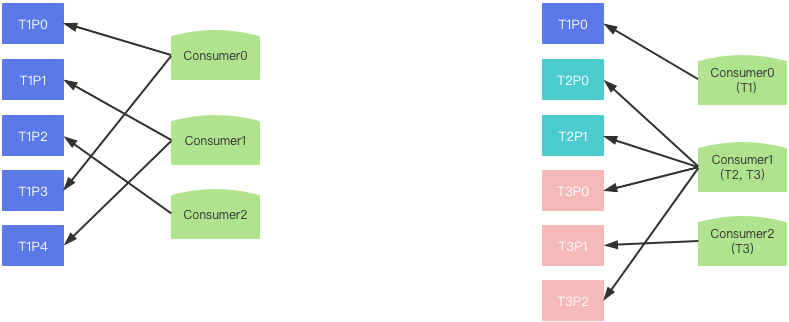
轮询策略 不同消费策略其实都可能会出现问题,主要原因是消费者组消费的主题不一致
粘性策略
前提条件:所有消费者消费主题相同
目的:尽可能不更改现有消费者的分区关联
对宕机的消费者对应的分区根据范围策略分配
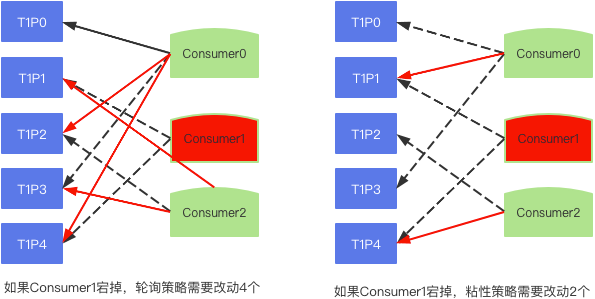
粘性策略 合作策略
其实就是粘性策略,只是可以进行自定义分配操作
重平衡(重新平衡)
重平衡操作会让消费者暂停消费,影响吞吐量
触发时机:
- 新增或删除消费者
- 消费者订阅的主题信息发生变化
- 主题的分区发生变化
消费案例
1 | public class Consumer { |
协调器(Coordinator)
作用:管理消费者组
确定位移主题的哪个分区保存当前消费者组的消费偏移量数据
位移主题:是Kafka为了保存消费者消费进度的主题,早期时消费进度是保存在zookeeper中,但zk不适合这种高频写操作;这个主题的默认分区数量是50个
分区编号=Math.abs(groupId.hashCode) % 位移主题的分区数量
计算出来的分区编号所对应的Leader副本所在的Broker就是协调器的Broker
偏移量提交
手动提交
1 | public static void main(String[] args) { |
提交指定偏移量
1 | public static void main(String[] args) { |