生产数据案例
改pom.xml
1 | <dependencies> |
写样例
1 | public class Producer { |
发送数据的基本原理
生产数据的准备
基本流程
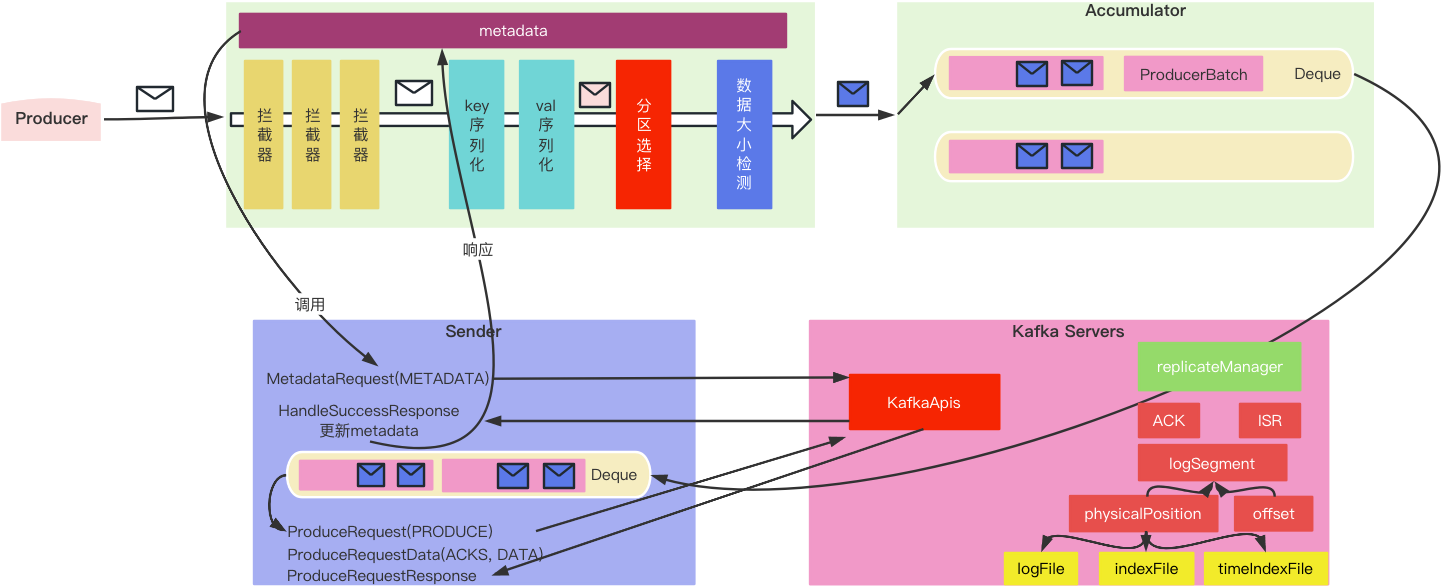
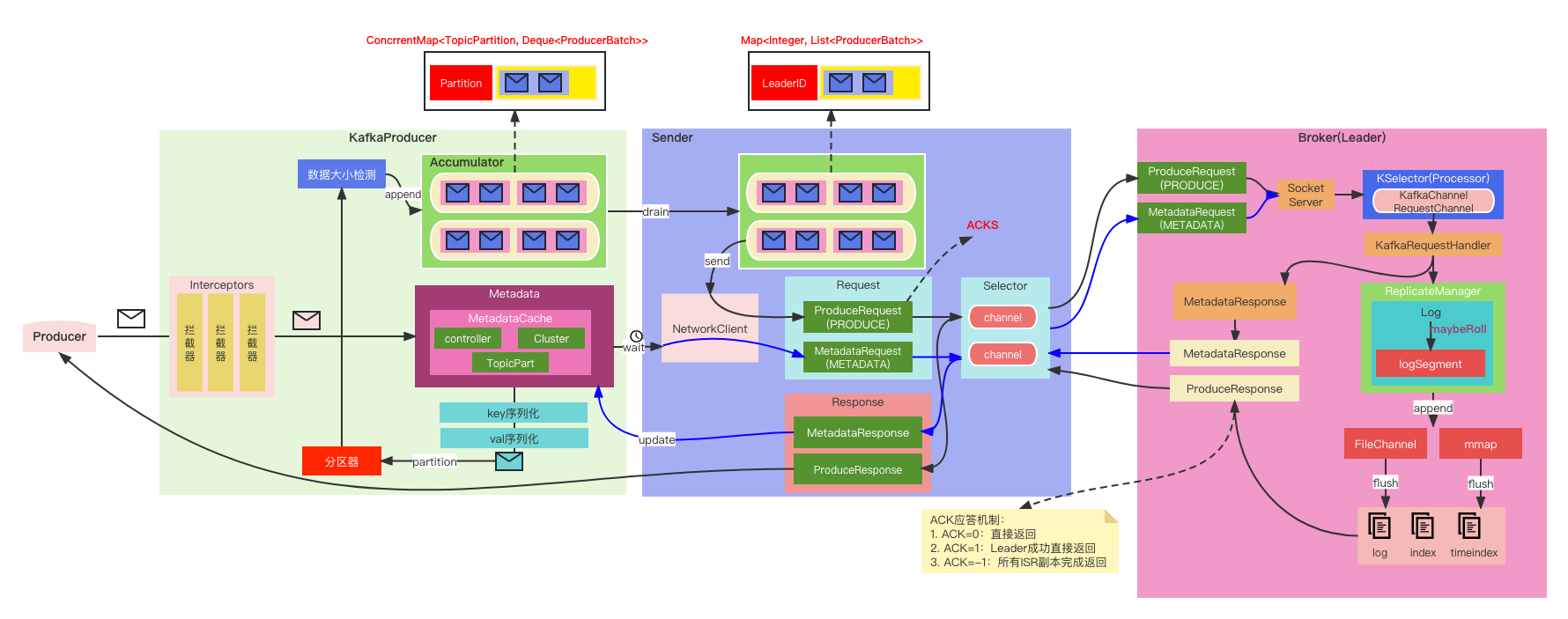
- Producer生产数据,将消息封装成ProducerRecord发送到Accumulator
- 在发送之前执行了拦截器中的拦截功能、对key、val序列化、选择分区与数据大小检测等过程
- 分区选择需要一些元数据,所以在分区选择之前需要通过Sender请求元数据信息
- 将数据大小检测合格的数据放入指定Deque的ProducerBatch中
- 队列中的ProduceBatch默认最大容量16KB,如果ProduceBatch中存放时可能放不下,如果放不下就要重新找一个Deque(对应分区)(负载均衡)创建ProduceBatch存放
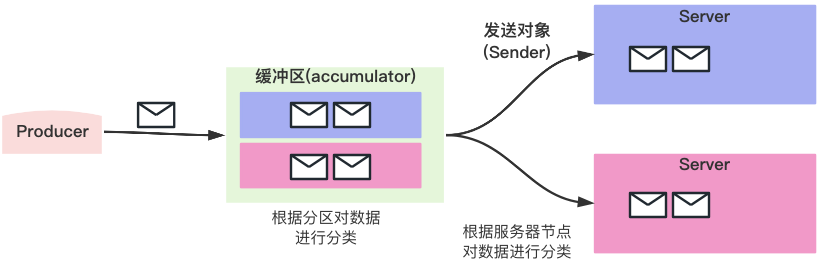
- Sender从Accumulator(缓冲区)获取数据并转换,按分区方式(Accumulator)转换为按节点方式(Sender)
- Sender发送请求,将数据发给Kafka Server
- Kafka Server中的副本管理器(replicaManager)根据一些参数(如ACK、ISR)对文件进行处理,根据LogSegment找到偏移量和物理地址,最终写入到三个文件(logFile、indexFile、timeIndexFile)
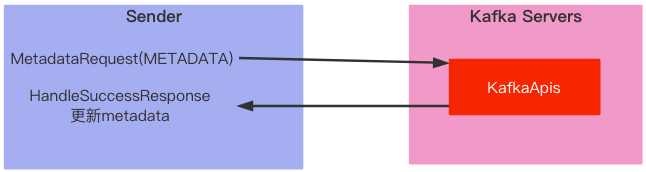
如何获取元数据?
自定义拦截器
1 | public class MyProducerInterceptor implements ProducerInterceptor<String, String> { |
分区选择
- 如果指定分区号,则直接使用
- 如果没有指定,则采用分区器决定分区
- 如果没有指定key,则会从所有分区中随机选择一个进行存放
- 如果指定了key,则会将key进行散列后和分区数量取余
数据大小检测
判断当前数据大小是否太大,分别与maxRequestSize(默认1M)和totalMemorySize(默认32M)比较,太大则抛出异常。
数据生产时出现问题
Accumulator中的Deque里面是是分区和数据;而Sender中的是节点和数据
当ProducerBatch满的的时候,就需要根据分区规则重新计算一个分区创建新的ProducerBatch
Segment:分段日志文件
日志文件不是一个完整的文件,而是根据大小分成几段(segment),默认是1GB
日志滚动条件
- segment log的大小已经不够放这次的消息
- 大于指定的时间
- 索引文件满了
- 时间索引满了
- 偏移量大于Int最大值
ACK:服务器应答机制
目的:保证数据可靠性的同时性能不能损失严重
实现方案:
- 所有Leader和Follower全部接收成功
- 所有Leader和半数以上的Follower全部接收成功
Kafka采用的方案:Leader+同步Follower的方案实现ACK应答机制,保证数据可靠
三个级别:
- ACK=0:直接返回;客户端发送数据后无需等待服务器将数据保存成功就可以发送下一条,不会重复发送
- ACK=1:Leader成功直接返回;Leader数据保存成功了
- ACK=-1 或 all:所有ISR副本完成返回;Leader数据和ISR集合中的所有副本保存成功,还要判断是否大于最小同步量(
min.insync.replicas)
同步机制
ISR:In-Sync Replica(同步副本)
这里所谓的同步指的是副本之间的数据相差不多
OSR:Out-Sync Replica
OSR中的副本数据和Leader数据差的比较多
ISR收缩效果:定时器
数据差的多:指的是和leader数据同步时间大于30s(之前的版本可能还与数据有关)
同步过程:Follower会启动数据同步线程,然后向Leader发送同步(Fetch)请求
偏移量
要解决的问题:Leader数据没有完全同步到Follower中,那么消费者如何消费数据?
Kafka设定了一些与数据偏移量相关的属性,用于判断消费者的消费情况与数据同步情况
所谓的偏移量其实就是数据在日志文件中的位置,从0开始
主要有三个属性:
- LogStartOffset(LSO):日志起始偏移量
- LogEndOffset(LEO):日志下一个偏移量
- highWatermark(HW):数据访问的水位线,消费者只能访问HW之前的数据,不能访问HW及HW之后的数据
- Leader的HW应该为所有副本中最小的LEO值
- Follower的HW应该为Leader中的HW和Follower中的LEO较小的值
- 更新:Follower抓取数据时,Leader会比对所有副本的LEO值,取最小值;Follower抓取数据时,Leader会返回给Follower HW,Follower会对比自己的LEO,取小的值作为Follower的HW
总结