数据存储演化
单点数据存储
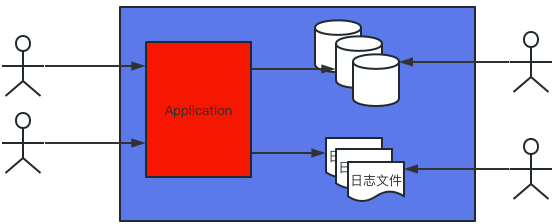
存在的问题:
- 所有应用都在单点上,共享资源,会导致资源不足
- 所有的请求都访问单点,所以性能会下降
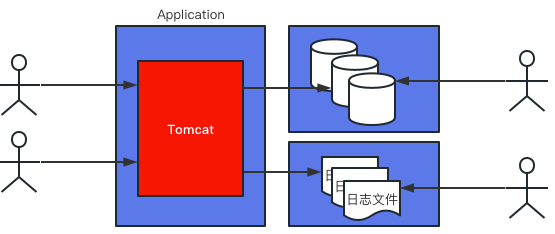
存在的问题:
单点存储服务,存在单点故障
分布式存储
多台机器形成集群,通过负载均衡降低单点的访问负载
大数据中经典的架构模式:主从
集群环境
Master:
- 存储集群的节点信息和状态;
- 监听节点信息的磁盘状态;
- 管理元数据信息,调度读写请求
- 选举存储主从节点
数据存储
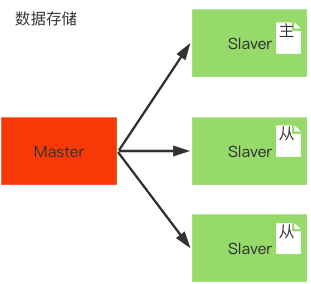
读数据请求可以访问任意节点
写数据时,每个数据节点都写还是写一个?
- 每个节点都写:数据冗余,浪费存储空间,但增强可靠性
- 就写一个节点,让数据均匀分布在不同节点
- 分布式存储中,数据存储节点一般都是要将数据均匀分布在不同的节点,并且数据节点应该进行备份,增强可靠性
- 新的问题:对于请求,如何知道请求的数据在哪个节点?
- 基本数据存储依靠节点路由操作(hash取余)
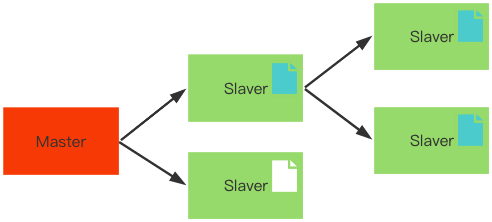
备份数据谁来写?
数据备份分为两种:
- 所有数据都是相同级别,统一写
- 将数据写入到其中一个主节点,由这个节点写入到其它备份节点中
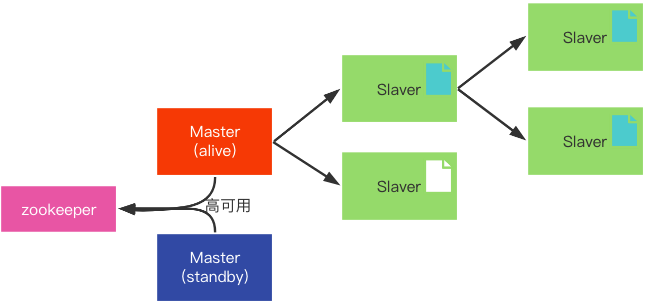
高可用
分布式数据计算
分布式数据计算是一种把需要进行大量计算的工程数据分割成小块,由多台计算机分别计算,数据在各个计算机节点上流动,同时各个计算机才能以某种方式访问数据共享数据,最终分布式计算后的输出结果被持久化存储和输出。
分布式计算比起其它算法的优点:
- 稀有资源可以共享
- 通过分布式计算可以在多台计算机上平衡计算负载
- 可以把程度放在最适合运动它的计算机上